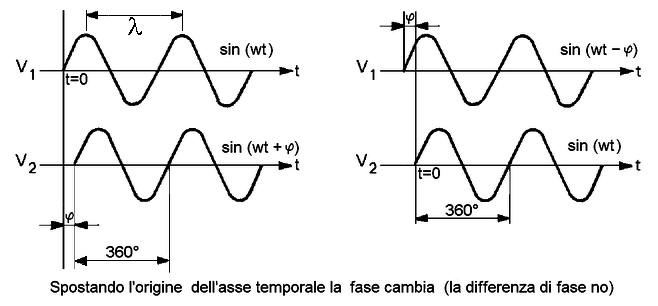
La fase,
udibilità
27 dicembre
2014, ultima revisione 13 febbraio 2017
di Mario Bon
Si veda anche: Human Hearing - Part 2 -
Phase Distortion Audibility di Mark Sanfilippo
Quanto segue vale per i fenomeni di propagazione in mezzi
non dispersivi.
Mezzi dispersivi e non dispersiviL’aria rispetto alle variazioni di pressione incontrate in campo audio, si comporta
come un mezzo non dispersivo. Ciò significa che la velocità di propagazione è
la stessa a tutte le frequenze (audio). Ciò comporta che un impulso non
cambia forma durante la propagazione. Per tale motivo il timbro di un suono
emesso da una sorgente puntiforme non dipende dalla distanza che il suono ha
percorso. Quando le variazioni di pressione superano un certo valore
anche l’aria diventa un mezzo dispersivo. Ciò si verifica, per esempio, con
il tuono. In prossimità del punto dove è caduto il fulmine, il tuono è una
esplosione. Man mano che la distanza dal punto di caduta del fulmine aumenta,
il suono si “sbrodola” e diventa un
brontolio. Questa variazione dipende dal fatto che la velocità di fase delle componenti spettrali del tuono non è costante con la frequenza. Mezzi dispersivi = velocità di fase dipendente dalla
frequenza Mezzi non dispersivi = velocità di fase non dipendente
dalla frequenza |
Una sinusoide è caratterizzata da tre grandezze: ampiezza, frequenza e fase.
Matematicamente la funzione seno si rappresenta come segue:
|
y = A sin (wt + j) |
Dove: A = ampiezza j = fase
w = 2 p f
(pulsazione) con f =
frequenza t = variabile indipendente |
Il valore della fase si misura radianti. Ora il valore di j dipende dalla scelta dell'origine dell’asse
temporale.
Ne segue che, data l’omogeneità del tempo, il valore della
fase di una sinusoide, in sé, non ha significato fisico (non incide, non è
causa).
Per un’onda sinusoidale che si propaga l’espressione è
leggermente diversa:
|
y = A sin (wt + kx) y rappresenta un
segnale sinusoidale con frequenza f che si propaga lungo x con velocità c. La velocità c è contenuta in k = w/c Segnale monocromatico |
Dove: A = ampiezza w = 2 p f
(pulsazione) f =
frequenza j = fase
= kx t = tempo
(variabile indipendente) x x = spazio k = numero d’onda
= w/c c =velocità di propagazione del segnale l =
lunghezza d’onda = c/f |
Anche per le onde
progressive, in virtù della omogeneità del tempo, è possibile spostare il
sistema di riferimento temporale a piacimento. Le differenze di fase tra le componenti
spettrali di un segnale, invece, non dipendono dalla scelta della origine
dell’asse temporale ed hanno
significato fisico (incidono, sono causa).
Il tempo è omogeneotutti gli istanti sono equivalenti, non esistono istanti privilegiati,
il tempo, in quanto tale, non è causa. Dalla omogeneità del tempo discende la conservazione
dell’energia. |
Ha senso parlare di
differenze di fase solo per segnali sinusoidali puri o nel confronto di segnali
sinusoidali della stessa frequenza in regime stazionario. Per i segnali fisici si deve considerare il “ritardo
di gruppo”. Per segnali fisici non ha
senso parlare di “fase” ma si devono considerare le relazioni di fase tra le
componenti spettrali.
Segnali Fisici o Segnali OsservabiliTutti i segnali fisici hanno un inizio e una fine e quindi
spettro limitato ed energia finita. Sono rappresentati da funzioni monodrome
a quadrato sommabile. In natura i segnali sinusoidali puri non esistono
(dovrebbero avere durata infinita => vedere Principio di Heisemberg). Si
veda la “Teoria Unificata dei Segnali Osservabili” |
Invarianza in forma
Sia dato un sistema lineare, sia dato lo stimolo (un segnale
fisico). Supponiamo che lo spettro dello stimolo sia limitato all’intervallo di
frequenza delta(f) e che, nello stesso intervallo delta(f), il sistema presenti
fase lineare (o fase minima con fase
nulla) e che la propagazione del segnale, all’interno del sistema, sia non
dispersiva. In queste condizioni la forma nel tempo della risposta è proporzionale alla forma nel tempo dello
stimolo (trascurando l‘eventuale tempo
di propagazione costante).
risposta(t) = K stimolo(t) dove K è una costante.
Quando ciò avviene si dice che il sistema conserva la forma
dello stimolo o che è “invariante in forma”.
Le sinusoidi sono intrinsecamente invarianti in forma per
trasformazioni lineari (omeomorfismi).
Per esempio un amplificatore è un dispositivo a fase minima. Supponiamo che la sua bada
passante si estenda da 2Hz a 200 kHz. Ne segue che la risposta in fase è nulla da circa 20 a 20000 Hz. Ne
segue che qualsiasi stimolo con spettro limitato tra 20 e 20000 Hz risulta invariante in forma. È invece arduo
ottenere l’invarianza in forma per un diffusore acustico se non in modo
approssimato, in una ristretta zona di spazio ed nel ristretto range di
frequenze compreso tra 500 e 2000 Hz
(circa). Fortunatamente l’apparato uditivo risulta sensibile all’eccesso di
fase proprio in questo stesso range di frequenza. L’ostacolo principale, con i
diffusori acustici, è la diffrazione ai bordi che può essere ridotta ma non
eliminata..
Suoni uguali e criterio di valutazione
Un suono può essere caratterizzato
da durata, altezza, intensità e timbro. In alternativa si può utilizzare il
segnale analitico (inviluppo e fase istantanea) o ancora una funzione monodroma nel tempo o lo spettro
complesso nel dominio della frequenza.
Affinché due suoni siano uguali è necessario che abbiano la
stessa durata, altezza, intensità e timbro. Il timbro è, per definizione,
quella qualità che consente di distinguere due suoni con durata, altezza,
intensità uguali. Ne segue che due suoni con durata, altezza e intensità
diversi sono, in generali, diversi. Il timbro è legato allo spettro complesso
del segnale e si misura con l’analizzatore di spettro.
Per determinare se l’apparato uditivo discrimina le
variazioni delle relazioni di fase tra le componenti spettrali di un suono, si
devono varificare due cose:
-
Se la variazione della fase determina una diminuzione della intelligibilità
del parlato
-
se la variazione della fase determina una variazione del
timbro.
Tali variazioni possono essere presenti ma non udibili ed in
tal caso si dovranno stabilire i limiti di udibilità e la JND..
Alcune cose già si sanno: per esempio è noto che se un suono
dura meno di circa 20 milli secondi l’apparato uditivo non riesce ad associarlo
da un timbro. In sostanza tutti i suoni brevi appaiono come un “click”
indistinto”.
Bisogna quindi prendere un segnale (A) e farne una copia
(B). Alterare le relazioni di fase in B ma in modo che durata, intensità e altezza non cambino. A questo punto si può
verificare se c’è una alterazione udibile tra A e B.
Teorema di Conservazione dell’Informazione
Il Teorema di Conservazione dell’Informazione stabilisce che
|
in un
sistema a fase minima l’informazione si conserva |
Ciò significa che, in un sistema a fase minima, la risposta
contiene tutte le informazioni presenti nello stimolo anche se attenuate e
ruotate. In tali condizioni le informazioni possono essere completamente
recuperate. Infatti un sistema è a “fase minima” quando esiste l’inversa della
sua funzione di trasferimento H(jw).
Applicando alla risposta l’inversa della funzione di trasferimento del
sistema si riottene lo stimolo.
H(jw) funzione di
trasferimento del sistema (trasformata di h(t))
H-1(jw)
inversa della funzione di
trasferimento del sistema (tale che H-1(jw) H(jw) =1)
Diamo la dimostrazione nel dominio della frequenza
|
Vout(jw)= H(jw) vin(jw)
|
La risposta è il prodotto dello stimolo e della funzione
di trasferimento |
|
H-1(jw)
Vout(jw)= H-1(jw)
H(jw) vin(jw) |
Moltiplichiamo a destra e a sinistra per l’inversa di
H(jw) |
|
H-1(jw)
Vout(jw)= vin(jw) |
c.v.d. lo stimolo è uguale al prodotto della risposta per
l’inversa di H(jw) |
Un esempio di applicazione del teorema della conservazione
dell’Informazione è la “equalizzazione” che, nelle normali condizioni, è limitata
dal rumore e dalle non linearità del sistema in esame.
Ricordiamo che:
|
condizione
necessaria affinché un sistema sia a fase minima è che il segnale si propaghi
dall’ingresso all’uscita attraverso un unico canale non dispersivo (o con
modalità riconducibili a questa). |

Nei diffusori acustici la diffrazione ai bordi impedisce che questa condizione necessaria si realizzi.
L’ aria secca, in assenza di gradienti di temperatura e per suoni non troppo forti, si comporta come un mezzo non dispersivo. Quindi gli impulsi emessi da sorgenti estese (che si propagano per onde piane) conservano la stessa forma perché il ritardo di gruppo non cambia durante la propagazione.
I suono prodotti da sorgenti puntiformi (che si propagano per onde sferiche) conservano la forma ma si riducono in ampiezza man mano che si allontanano dalla sorgente.
Eccesso di fase (distorsione di fase)
Il diffusore acustico non è, a rigore, un sistema a fase
minima a causa della diffrazione ai bordi (e di mille altre cose). Nel caso dei
diffusori acustici si valuta la risposta in fase e si calcola l’eccesso di fase.
L’eccesso di fase è la differenza tra la risposta in fase effettiva del
sistema F1 e la risposta in fase F2 che avrebbe se fosse un sistema a fase
minima. Quindi
Eccesso di fase = F1-F2
La risposta F2 si ottiene dal modulo della risposta del
D.U.T. attraverso un calcolo che
richiede la trasformata di Hilbert.
L’eccesso di fase viene identificato con la “distorsione di fase”.
L’eccesso di fase rappresenta l’alterazione della fase relativa delle
componenti spettrali rispetto al sistema “equivalente” a fase minima. Ne segue
che “eccesso di fase nullo” non significa necessariamente che il ritardo di gruppo
sia nullo ma che corrisponde a quello di un sistema a fase minima..
Prescindendo dalla diffrazione ai bordi (che esiste sempre)
si possono fare delle considerazioni generali sui diversi tipi di sistemi:
|
Sistemi monodia o a più vie coassiali (di dimensioni contenute) |
Se i centri acustici sono coincidenti la condizione i fase
minima |
|
Sistemi planari estesi |
La condizione di fase minima può essere approssimata ad
una distanza molto maggiore rispetto alle dimensioni della sorgente |
|
Sistemi a due vie |
Esiste almeno un
direzione lungo la quale, ad una certa distanza, almeno teoricamente si può realizzare la condizione di fase
minima |
|
Sistemi con più di due vie |
In teoria è ancora possibile ottenere le condizioni di
fase minima allineado opportunamente i centri di acustici di emissione degli
altoparlanti. Si restinge però la spazio dove ciò può avvenire. |
|
|
|
Evidentemente l’arrivo
nel punto di ascolto delle riflessioni distrugge (con l’interferenza) la
condizione di fase minima. Fortunatamente l’apparato uditivo riesce a
riconoscere ed a correlare un suono con
le sue riflessioni che vengono usate per rinforzare il suono stesso (integrazione).
In virtù di ciò possiamo limitare la condizione di fase minima al solo suono diretto.
Il suono diretto ed
il suono riflesso sono separabili nel tempo: le qualità primarie del suono sono
associate al suono diretto, le qualità secondarie (come la spazialità)
dipendono dal suono riflesso. Su questa evidenza sperimentale Amar G. Bose ha
basato la progettazione della serie 900.
Udibilità della inversione di polarità o della “fase assoluta”
|
|
|
|
Segnale
“normale” |
Segnale con
polarità invertita |
Non si dovrebbe parlare di
“fase assoluta” ma di
“inversione di polarità”.
L’inversione di polarità del segnale (la trasformazione da
y a
–y)
-
non muta il modulo
dello spettro del segnale
-
non muta la fase relativa tra le componenti spettrali del
segnale
-
non muta l’energia trasportata dal segnale (che è
proporzionale a |y|2)
-
non muta l’altezza, durata, intensità e timbro
In sostanza l’inversione della polarità del segnale non
cambia le informazioni contenute e trasportate dal segnale (da qualsiasi
segnale). L’inversione di polarità è una trasformazione lineare che non
introduce distorsione.
|
Tecnicamente l’inversione di polarità del segnale si
ottiene applicando successivamente due trasformazioni di Hilbert al segnale: H[H[y(t)]] = -y(t) |
L’inversione della polarità del
segnale audio viene percepita, in condizioni particolari e con segnali
particolari, a causa di difetti di simmetria del sistema di riproduzione.
Ne segue che alcuni transienti particolarmente intensi, presenti nei programmi musicali,
saranno riprodotti meglio se il diffusore è collegato con una certa polarità.
Ergo invertire la polarità
dell’impianto stereo ha un senso molto relativo: bisognerebbe scegliere la più
adatta per ogni brano musicale (se non con ogni transiente). Quello che è
certo è che, se invertendo la polarità
dei diffusori (il rosso con il nero per intendersi) si percepisce una
differente qualità nella riproduzione di certi transienti, significa che il
sistema soffre di una qualche
asimmetria (in sostanza produce
abbondante distorsione di armonica pari con grandi segnali).
Va anche ricordato che la
distorsione di forma è generalmente ben tollerata quindi la distorsione
prodotta deve essere “abbondante”.
Va poi tenuto conto di un’altra
cosa: il nostro sistema uditivo processa musica, parlato e rumore in aree
diverse del cervello. Una quarta area è deputata alla localizzazione della
sorgente.
Quando si fanno dei test con
segnali artificiali (onde quadre, impulsi o simili) questi, non essendo parlato
e se non riconosciuti come musica, vengono processati come “rumore” ed i
risultati dei test così ottenuti non sono direttamente riferibili all’ascolto
della musica.
Ne segue che, anche se si riesce a distinguere la polarità di alcuni suoni “artificiali” non è detto che la stessa cosa sia possibile con la musica. In linea di principio, con programmi musicali, e considerata anche la fisiologia dell’orecchio, la inversione contemporanea della polarità di entrambe i canali stereo non viene percepita. Al contrario l’inversione di polarità di un solo canale dello stereo è facilmente avvertita (carenza di bassi e mancanza del canale centrale virtuale) anche se non proprio da tutti (serve un minimo di allenamento).
Ci sono poi altre situazioni più difficili da individuare per
esempio quando, in un sistema a tre vie, solo i tweeter risultano essere in
controfase (ancor più se si parte da una situazione di quadratura
all’incrocio).
Udibilità della alterazione fase relativa
Tutto sta ad intendersi sulle definizioni.
Prendiamo un sistema a due vie ben progettato con frequenza
di cross-over compresa tra 1500 e 3000 Hz. La risposta in frequenza in
condizioni anecoiche potrebbe essere, per esempio, quella mostrata nella figura
che segue.
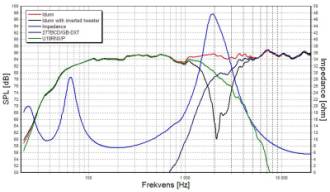
Se invertiamo la polarità di uno solo
dei due altoparlanti, non solo avvertiremo una differenza nella riproduzione,
ma misureremo un bel buco nella risposta in frequenza (come mostrato in figura,
in nero). L’inversione della polarità ha invertito la fase di una parte dello
spettro del segnale. Il risultato è udibile e misurabile.
Ma è udibile perché è cambiata la risposta o perché è cambiata la
fase? In questo caso è molto più udibile la variazione di risposta in
frequenza. A parte casi rari (due
altoparlanti che si sovrappongono in quadratura su una regione di frequenza
molto stretta o quando si utilizzano reti all_pass) una variazione di fase è sempre
accompagnata da una variazione di ampiezza. Resterà quindi l’incertezza nello
stabilire se le variazioni udite dipendano dalla alterazione della fase o dall’alterazione dell’ampiezza.
In letteratura la distorsione di
fase è stata valutata con l’uso di reti all_pass. Il risultato è che la
variazione di fase introdotte da una rete all pass sono udibili. Esperimenti
interessanti ma poco utili per quanto riguarda i diffusori acustici. Le reti
all pass alterano la fase con continuità su bande di frequenza nell’ordine di
una decade mentre l’inversione di polarità di una via provoca una brusca
variazione di fase (di 180°) su tutto il range di funzionamento dell’
altoparlante. Una rete all pass del
primo o secondo ordine non può simulare efficacemente nemmeno un
disallineamento temporale tra le sorgenti.
Una rete all pass non modifica
lo spettro del segnale ma ne altera il fattore di cresta. Ci si può quindi chiedere
se la variazione timbrica percepita dipende dalla fase “in sé” o dalla
variazione del fattore di cresta.
Udibilità dell’allineamento temporale.
Questo aspetto è stato indagato, molti anni fa, dall’ing
Gandolfi in un articolo pubblicato sulla rivista SUONO. Le conclusioni furono
incerte nel senso che il miglioramento dell’allineamento temporale tra gli
altoparlanti comporta sempre il miglioramento della riproduzione (almeno nella
riproduzione di alcuni strumenti) ma è difficile stabilire se ciò sia dovuto al
miglioramento della risposta impulsiva o al miglioramento della risposta in
frequenza (ricordiamo che il sistema utilizzato da Gandolfi era affetto da diffrazione ai bordi e quindi non
era a fase minima né poteva diventarlo).
|
|
|
|
Sistema
utilizzato da Gandolfi: il tweeter veniva avanzato o arretrato fino a trovare
il miglio allineamento temporale |
Woofer e
tweeter non allineati e allineati su piani sfalsati che introduce diffrazione
ai bordi |
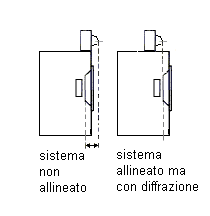
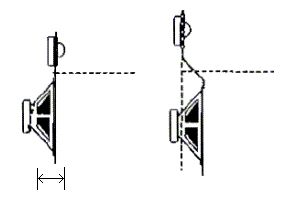
Nel caso dell’allineamento temporale delle sorgenti si deve
verificare se è più importante la diffrazione ai bordi o il disallineamento
temporale. Entrambe alterano sia risposta in frequenza che la risposta all’impulso.
Esperimento di Schroeder
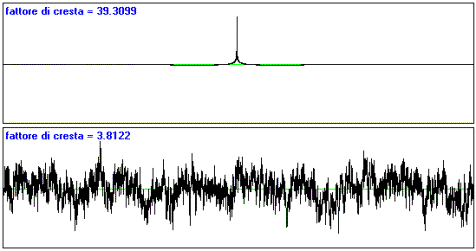
Randomizzando la fase di un impulso si ottiene un rumore.
Questi due stimoli “suonano” in modo completamente diverso anche se hanno lo
stesso spettro di potenza. Per Schroeder ciò dimostra che la alterazione delle
relazioni di fase è udibile. L’impulso ed il rumore però sono suono
completamenti diversi per timbro e durata (l’altezza non è riconoscibile,
ampiezza non è confrontabile ad orecchio) quindi due segnali vanno classificati come due suoni diversi che
incidentalmente hanno lo stesso spettro di potenza. Per dirla tutta, anche lo
sweep lineare presenta lo stesso spettro di potenza dei sue segnali proposti.
|
Impulso (delta di Dirac) |
Spettro bianco |
Questi tre segnali differiscono per le relazioni di fase
ma anche per la durata, l’altezza e
l’intensità. |
|
Rumore bianco |
Spettro bianco |
|
|
Sweep lineare |
Spettro bianco |
In sostanza l’esperimento di Schroeder non dimostra nulla
perché confronta tra loro segnali diversi
che, tra l’altro, non sono
nemmeno segnali musicali (quindi in ogni caso i risultati non sono riferibili
alla percezione della musica). Allo stesso modo è altrettanto superficiale sostenere
che le variazioni di fase non siano udibili.
Inversione dell’asse temporale
L’esperimento di Schroeder pone una domanda: esistono due
suoni musicali che differiscano solo per le relazioni di fase mantenendo
inalterato lo spettro di potenza, durata, altezza, intensità , i valori di
picco, ecc.? Si, esistono. Anzi, per ogni suono musicale, ne esiste un altro
che differisce solo per le relazioni di fase.
|
|
|
|
Segnale
“normale” |
Segnale a
tempo invertito |
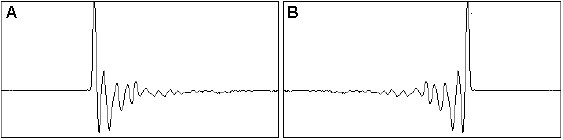
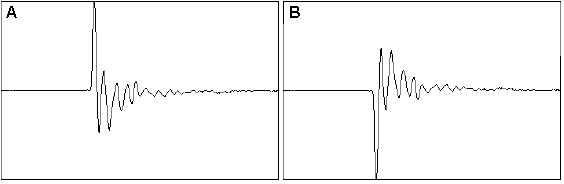
Si registri su nastro una nota prodotta dal pianoforte. Si
ascolti tale segnale normalmente e invertendo il verso di percorrenza del
nastro. Questa operazione equivale alla inversione del tempo. Normalmente si
sente una nota di pianoforte (A), “all’indietro” il suono assomiglia a quello della fisarmonica (B). L’inversione
del nastro ha prodotto lo scambio del transitorio di salita con quello di
discesa: la trasformazione produce una
variazione del timbro udibile dal 100% dei soggetti normodotati. Ora questi due
segnali hanno:
-
stesso spettro di potenza (modulo dello spettro uguale)
-
stessa durata, intensità e altezza
-
stesso valore picco, fattore di cresta, energia, fattore di
forma, valore RMS, ecc.
-
lo stesso inviluppo ma a tempo invertito (f(t) e f(-t) )
l’unica cosa che cambia tra i due suoni a livello spettrale,
e lo si capisce anche solo per esclusione, sono le relazioni di fase tra le
componenti spettrali alle quali va attribuita la responsabilità della
alterazione del timbro. Ciò dimostra che le alterazioni delle relazioni di fase
modificano il timbro anche in segnali di uguale durata, altezza,
intensità e contenuto spettrale.
Si dimostra matematicamente che l’inversione del tempo
corrisponde alla alterazione delle sole
relazioni di fase. Per farlo si devono ricordare le proprietà della Trasformata
di Fourier (TDF ma lo stesso vale per la DFT e la FFT). Detto x(t) il segnale,
invertendo il tempo si ottiene x(-t):
FFT[x(t)] = X(jw)
FFT[x(-t)] = X(-jw) = X*(jw) dove l’asterisco indica il complesso coniugato.
In sostanza la FFT del segnale con asse del tempo invertito è il complesso
coniugato del segnale di partenza. Se usiamo la notazione complessa
|
X(jw) = a(w) + ib(w) |
segnale |
|
X*(jw) = a(w) - ib(w) |
complesso coniugato |
|
| X(jw)| = | X*(jw)| |
I moduli sono uguali |
Vediamo che invertire il verso dell’asse temporale
corrisponde a cambiare di segno la parte immaginaria del segnale trasformato.
Ciò lascia invariato il modulo ed inverte il segno della sola fase.
L’inversione di polarità, invece, inverte il segno sia della
parte reale che della parte immaginaria (per la linearità della FFT). Quindi
invertire la polarità o invertire il segno della sola parte immaginaria non è
la stessa cosa. L’inversione del tempo si può fare solo su segnali registrati.
Detto questo, resta ancora da stabilire cosa succede quando
l’alterazione della fase non è così traumatica: per esempio cosa succede quando
la fase viene alterata su una banda limitata di frequenze.
|
|
|
In questa figura sono rappresentate quattro versioni dello
stesso segnale con le relative relazioni tra le loro trasformate. -
primo quadrante (in alto a destra) FFT[v(t)]=X(jw) = a+jb -
secondo quadrante (in alto a sinistra) inversione del tempo X(-jw)= a-j b -
terzo quadrante (in basso a destra) inversione della polarità e del tempo
–X(-jw) = -(a-jb)
-
quarto quadrante (in basso a sinistra) inversione della polarità –X(jw) = -(a+jb) si notino le relazione con il segnale complesso coniugato
X*. I segnali nel primo e secondo quadrante differiscono per il
segno della parte immaginaria (dello spettro) gli altri due si ottengono con l’inversione di polarità. |
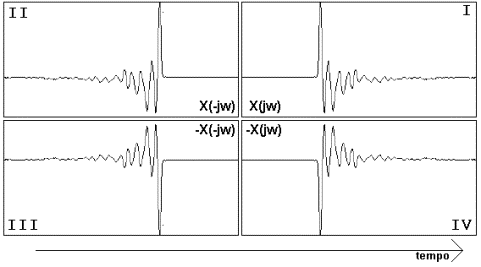
Udibilità delle alterazioni delle relazioni fase nel parlato
Abbiamo visto situazioni in cui le variazioni delle
relazione di fase comportano l’alterazione del timbro.
|
Nel
parlato la priorità è conservare la
intelligibilità. L’apparato
uditivo tollera quelle variazioni delle relazioni di fase che non pregiudicano l’
intelligibilità. Si
capisce quindi che esiste un intervallo di tollerabilità. |
Fintantoché una “t” e una “p” vengono percepite
distintamente come “t” e “p” significa che l’alterazione delle relazioni di
fase è tollerata. Quanto la parola
“topo” non è più distinguibile dalla parola
”dopo” significa che la “distorsione di fase” è eccessiva. Quindi la
quantità da valutate è la ALCONS
|
ALCONS
(Articulation Loss of Consonates): misura l’intelligibilità del parlato
attraverso la percentuale di sillabe non riconosciute. Se vale zero significa
che il parlato è perfettamente intelligibile. Il massimo valore consentito è
pari al 15% Intelligibilità: L’intelligibilità è
una qualità della riproduzione del parlato che misura il rapporto tra il
numero di sillabe percepite correttamente rispetto al numero di sillabe
pronunciate. L’intelligibilità diminuisce in presenza di “fattori esterni”
quali riverbero, rumore ma anche distorsione (se si tratta di riproduzione).
E’ espressa in parti per
cento. Si veda anche Chiarezza. |
L’equivalente dell’ALCONS per i programmi musicale è la
“Definizione orizzontale” o “Trasparenza temporale” che è un aspetto della
Chiarezza.
|
Chiarezza (Clariry, Deutlichkeit, Definizione): Misura la capacità dell’ascoltatore di percepire distintamente
ogni nota anche nelle sequenze più veloci. In una sala la Chiarezza della
musica dipende dal rapporto (in decibel) tra il livello delle prime
riflessioni (entro i primi 80 millisecondi) e delle riflessioni ritardate
(oltre 80 millisecondi). Il livello delle prime riflessioni entro i primi 50
millisecondi determina invece l’intelligibilità del parlato. Il primo a
proporre un “indice di definizione” è stato Thiele utilizzando anche gli
studi di Haas. Oggi si preferisce fare riferimento all’indice di chiarezza
C80(3) ottenuto come media del C80 calcolato sul bande di ottava centrate a
500,1000 e 2000 Hz.
Secondo Reichardt il C80 rappresenta gli attributi di
“Trasparenza temporale” e “Trasparenza armonica” (note suonate in successione
rapida e note suonate contemporaneamente). La “Trasparenza temporale” e la
“Trasparenza armonica” sono anche conosciute, rispettivamente, come
“definizione orizzontale” e definizione verticale”. Per superare alcune
incertezze legate alla misura del C80 è stato introdotto da Kurer l’istante
baricentrico o “tempo centrale”. La “Trasparenza orizzontale” è interessante perché
può essere valutata soggettivamente ascoltando particolari brani musicali (di
partitura nota). Lo stesso vale per la “Trasparenza armonica”. |
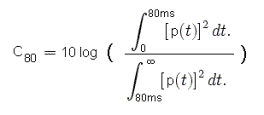
Quello che risulta da diversi studi, ma che dovrebbe essere
già noto da tempo a chi progetta diffusori acustici ed, in particolare, sistemi
a tromba, è che la distorsione di fase (l’eccesso di fase) deve risultare
particolarmente contenuto nel range di frequenza che va da circa 500 a circa
2000 Hz.
|
500 Hz |
68.8 centimetri |
|
1000 Hz |
34.4 centimetri |
|
2000 Hz |
17.2 centimetri |
Questo range di frequenza, non a caso, è anche quello più
importante per la localizzazione della sorgente (reale o virtuale). In questo
stesso range di frequenze cadono, purtroppo,
-
i break up delle membrane
-
l’effetto coincidenza dei diaframmi in carta
-
le risonanze causate dal rim.
Tutti questi fenomeni provocano alterazioni nella risposta
impulsiva (quindi nelle relazioni di fase).
Conclusioni
Per concludere l’alterazione delle relazioni di fase tra le
componenti spettrali del segnale provoca una alterazione del timbro (e su questo non ci piove) nelle opportune
condizioni tale alterazione è udibile come alterazione del timbro. Ne segue che
l’apparato uditivo è sensibile alle alterazioni delle relazioni di fase (e
all’eccesso di fase) . Se si considera l’intelligibilità del parlato (che
richiede condizioni più stringenti rispetto alla intelligibilità della musica)
si deve considerare tollerabile qualsiasi “distorsione di fase” che non
pregiudichi la intelligibilità del parlato. Ne segue che devono essere valutati
la ALCONS (per il parlato) e la Chiarezza (per la musica). Tecnicamente ciò
richiede che le relazioni di fase siano rispettate in un intervallo di due ottave centrato attorno a
1000 Hz.
L’eccessivo riverbero nell’ambiente produce un peggioramento
della ALCONS e della Chiarezza e, di conseguenza, maschera la risposta del
sistema di riproduzione.. Questq è
sostanzialmente la causa di giudizi soggettivi discordanti.
Tabella riassuntiva per sistemi di riproduzione stereo:
|
Causa |
Effetto |
Udibilità degli effetti |
|
Inversione
della polarità contemporanea dei due
canali |
Inversione
dell’impulso rispetto all’asse del tempo |
Sistemi
lineari: non udibile |
|
Sistemi non
lineari: udibile |
||
|
Inversione
della polarità di un canale |
Carenza
di bassi Mancanza
del canale virtuale centrale |
Udibile
99% |
|
Inversione della polarità di un altoparlante in
sistema multivia |
Variazione
di risposta in fase, frequenza e impulsiva |
Udibile (dipende dalle regioni di frequenza
interessate) |
|
Causa |
Effetto |
Udibilità degli effetti |
|
Allineamento
temporale degli altoparlanti in sistemi multivia |
Variazione
di risposta in fase frequenza e
impulsiva |
Udibile (dipende dalle regioni di frequenza
interessate) |
|
Applicazione
di filtri all pass allo stimolo |
Variazione
della risposta in fase e della risposta impulsiva |
Udibile (dipende dalle regioni di frequenza
interessate) |
|
Randomizzazione
delle relazioni di fase nello stimolo |
Variazione
della risposta in fase e della risposta impulsiva |
Udibile 100% (Schroeder) |
|
Inversione
del tempo dello stimolo per segnali musicali |
Variazione
delle sole relazioni di fase |
Udibile
100% quando
il transitorio di attacco è diverso dal decadimento |
La udibilità degli effetti dipende, in generale, dal tempo
di riverberazione dell’ambiente e dalle regioni di frequenza coinvolte dal fenomeno.
L’unica eccezione è rappresentata dalla inversione del tempo che è sempre
udibile. L’udibilità è massima se le
alterazioni delle relazioni di fase tra le componenti spettrali avviene tra 500
e 2000 Hz. L’inversione temporale dello stimolo, se il tempo di attacco e di
decadimento sono diversi, è sempre
udibile.
Appendice: La scala dei DO
Ottave a partire dal centro banda fissato a 1000 Hz (scala del DO)
|
15.625 Hz |
22 metri |
|
31.25 Hz |
11 metri |
|
62.5 Hz |
5.5 metri |
|
125 Hz |
2.75 metri |
|
250 Hz |
1.37 metri |
|
500 Hz |
68.8 centimetri |
|
1000 Hz |
34.4 centimetri |
|
2000 Hz |
17.2 centimetri |
|
4000 Hz |
8.6 centimetri |
|
8000 Hz |
4.3 centimetri |
|
16000 Hz |
2.15 centimetri |
La corrispondenza tra i limiti di udibilità, la lunghezza
d’onda, la distanza media tra le orecchie e la frequenza del DO è solo un caso?
Evidentemente non lo è perché la scala cromatica rispecchia le caratteristiche
dell’apparato uditivo e la distanza tra le
orecchie è una delle caratteristiche determinanti (per esempio determina i meccanismi di localizzazione
della sorgente).